
Avec la virtualisation et l’automatisation, on étoffe nos architectures et le besoin de load balancing est toujours plus présent. On va regarder aujourd’hui keepalived, remplaçant du couple pulse/nanny.
Introduction
Cet article vient dépoussiérer celui concernant le combo Piranha (l’UI pour LVS), pulsed et nanny. En effet, depuis la version 7, Red Hat a abandonné le support du pulse/nanny au profit de keepalived et haproxy. C’est toujours LVS, le module noyau qui opère en dessous mais on change la surcouche simplifiant l’usage.
J’ai eu l’occasion de mettre en oeuvre du keepalived sur du Red Hat 7 (donc en v1…) et sur du Red Hat 8 (v2) pour deux usages : faire le failover d’un httpd et faire du load balanicng L4 de protocole LDAP. Petit retour d’expérience et mini tutoriel de configuration. J’aborderai aussi l’automatisation avec Ansible de ce composant.
Découverte du logiciel
On est vraiment sur quelque chose de simple et efficace, un démon et un fichier de conf, un plaisir à utiliser :) On l’installe en 2 commandes :
dnf install keepalived
systemctl enable keepalived
Au premier abord, on a l’impression qu’il n’est pas très riche en fonctionnalités mais c’est mal le connaitre. Initalement, je pensais qu’il ne faisait que du failover local ce qui expliquerait l’ajout quasi systématique de HAproxy mais il n’en est rien. La documentation tient en une page, c’est complet même si un peu trop condensé :D
https://keepalived.org/manpage.html
Journalisation
J’aime bien avoir les logs dans un fichier dédié, ça se configure en ajoutant dans le fichier /etc/rsyslog.d/keepalived.conf :
local6.* /var/log/keepalived.log
Il faut aussi indiquer à keepalived quelle facility utiliser en éditant le fichier /etc/sysconfig/keepalived :
KEEPALIVED_OPTIONS="-D --log-facility=6"
Ne pas oublier de reload keepalived, rsyslogd et mettre un pti logrotate même si keepalived génère vraiment pas beaucoup de logs.
Failover simple
L’usage le plus courant de keepalived est d’avoir deux serveurs hébergeant une application en actif-passif, keepalived se chargeant de piloter le failover en activant une VIP sur le noeud actif.
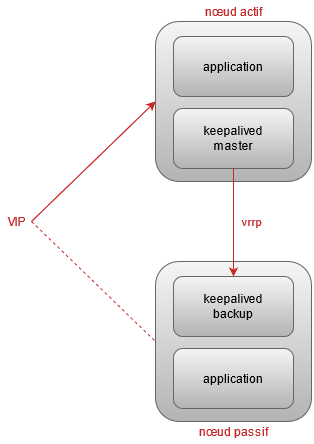
Si on n’a pas de besoin de scalabilité, c’est un très bon compromis pour gagner en résilience sans trop complexifier l’architecture. De plus, ça peut permettre de redonder des applications ne disposant pas de possibilité de clustering (avec certaines limites biensur). D’expérience, les mécanismes de haute dispo trop blingbling créent souvent plus d’incidents qu’ils en évitent :)
Le keepalived maitre envoie régulièrement des messages vrrp. Si un keepalived de backup n’en reçoit plus, il peut se proclamer maitre. Le keepalived maitre peut aussi déclencher une élection pour passer la main (typiquement, si l’application sur le noeud actif est tombée).
On va devoir configurer dans keepalived une VIP, un check de l’application et la communication entre les deux démons keepalived, tout se situe dans l’unique fichier keepalived.conf :
vim /etc/keepalived/keepalived.conf
Une première partie de la configuration concerne les paramètres du démon keepalived local, comme son nom ou le smtp à utiliser pour les notifications. Je n’ai pas eu besoin d’autre option mais comme vous pouvez le voir dans la doc, il y en un paquet !
global_defs {
router_id noeud1.toto.fr
smtp_server 127.0.0.1
smtp_connect_timeout 30
notification_email_from noeud1@toto.fr
notification_email {
admin@toto.fr
}
smtp_alert true #keepalived v2
}
On va maintenant configurer un routeur virtuel (vrrp_instance), c’est ce bloc qui va faire travailler plusieurs serveurs keepalived ensemble et piloter les VIP. On peut configurer plus d’un routeur virtuel mais dans la majorité des cas, un seul suffit. Voici un exemple minimal de conf :
vrrp_instance VIP {
state MASTER
priority 100
virtual_router_id 10
interface eth0
advert_int 2
authentication {
auth_type PASS
auth_pass toto
}
track_script {
check_failover
}
virtual_ipaddress {
192.168.0.10 label eth0:1
}
}
On a un routeur virtuel ayant comme identifiant 10, tous les membres communiquent en multicast avec le mot de passe toto. On veut une VIP 192.168.0.10 attachée à l’interface physique eth0 et nommée eth0:1 (pour la voir avec ifconfig). Notre noeud en particulier est configuré pour être le membre actif, la priorité vient départager des noeuds avec le même state (si backup multiple par exemple). Il enverra ses messages d’état toutes les 2 secondes. Enfin, il appelera périodiquement un script pouvant influencer son état (typiquement vérifier l’appli locale).
Et pour finir, il ne nous reste plus qu’à configurer le script (ou la commande) de check dont on parlait juste au dessus. Par exemple ici, on vérifie toutes les 5 secondes qu’il y a toujours un pocess httpd.
vrrp_script check_failover {
script "/usr/sbin/pidof httpd"
interval 5
}
Sur le noeud de backup ou noeud passif, il suffit de changer le paramètre state de MASTER vers BACKUP ainsi que le router_id dans la partie global_defs. Par défaut, les messages échangés entre les keepalived sont en multicast, ça simplifie la conf puisque pas besoin de lister les IP des autres noeuds keepalived. Normalement le couple virtual_router_id + auth_pass devraient empêcher toute interférence extérieure, d’autant plus si ils sont dans un VLAN dédié. Il arrive assez souvent que le multicast soit interdit ou que l’adressage IP ne le permette pas, dans ce cas il faut paramétrer keepalived pour faire du unicast. Il suffit d’ajouter deux directives dans le bloc vrrp_instance, exemple :
unicast_src_ip 192.168.0.1
unicast_peer {
192.168.0.2
}
TODO : Logs + ifconfig pour illustrer
Loadbalancer L4
Si notre application est un cluster ou si on a besoin de scalabilité, on va devoir partager les requetes vers plusieurs noeuds applicatifs actifs. Dans ce cas, keepalived en plus de faire son propre failover, va load balancer les requetes entrantes vers un pool de serveurs finaux dont il s’assuera la bonne santé.
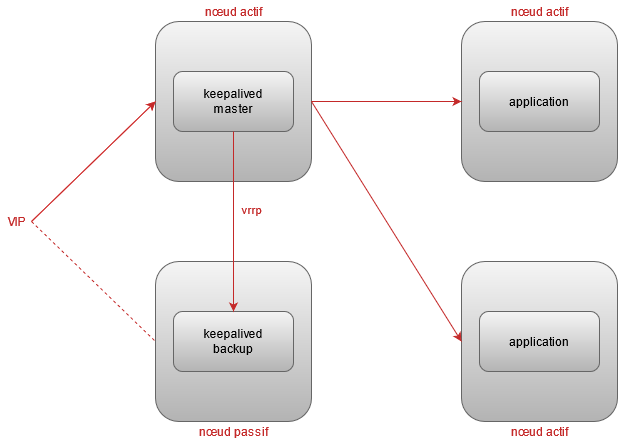
On reprend la même configuration que pour le mode failover à l’exception du script de check local :
global_defs {
router_id noeud1.toto.fr
smtp_server 127.0.0.1
smtp_connect_timeout 30
notification_email_from noeud1@toto.fr
notification_email {
admin@toto.fr
}
smtp_alert true #keepalived v2
}
vrrp_instance VIP {
state MASTER
priority 100
virtual_router_id 10
interface eth0
advert_int 2
unicast_src_ip 192.168.0.1
unicast_peer {
192.168.0.2
}
authentication {
auth_type PASS
auth_pass toto
}
virtual_ipaddress {
192.168.0.10 label eth0:1
}
}
On doit ajouter dans la configuration un bloc par service virtuel (une VIP + un port) dans lequel on déclarera nos serveurs applicatifs (appelés real servers), le check, la stratégie de loadbalacing (algorythme, poids, etc).
virtual_server 192.168.0.10 636 {
delay_loop 10 #interval check in seconds
protocol TCP
lvs_sched wrr #weighted round-robin
lvs_method NAT
persistence_timeout 7200
ha_suspend #if node is backup for current VIP, dont check real servers
# serveur applicatif 1
real_server 192.168.0.11 636 {
weight 100 #ratio used by lvs_scheduler
TCP_CHECK {
connect_port 636
connect_timeout 5
}
}
# serveur applicatif 2
real_server 192.168.0.12 636 {
weight 100 #ratio used by lvs_scheduler
TCP_CHECK {
connect_port 636
connect_timeout 5
}
}
}
La persistence
J’ai testé plusieurs alogorythmes sans voir d’impact important, par exemple entre le least connection et le round robin. Concrétement, de nos jours, toutes nos VM applicatives ont le même sizing, je ne vois pas trop de cas d’usage nécessitant une répartition non équitable des requetes vers les serveurs finaux. Il faut garder en tête que même avec un écart de poids important, par exemple 100 contre 1, le serveur avec le poids le plus faible recevra quand même des requetes (1 requête sur 100). Si on veut un serveur de backup dans un pool de real server, il faut utiliser la fonction suivante (dat transition :D)
Sorry server
Pour faire cours, si aucun serveur du pool n’est UP, alors on envoie en dernier recours vers ce serveur. Je pense que ça servait principalement pour afficher un message du style “Aucun serveur ne peut prendre en charge votre demande, essayez plus tard).
Un cas d’usage intéressant : J’ai un cluster de 3 noeuds, j’ai une VIP pour les accès clients (des lectures majoritairement) que je veux loadbalancer sur seulement 2 noeuds, gardant le 3ème noeud pour les traitements internes. Néanmoins, j’aimerai que ce noeud soit là en backup si les deux autres sont NOK. Il me suffit d’ajouter dans le bloc virtual_server :
sorry_server 192.168.0.13 636
Pas de check dans ce cas, pourquoi faire, on est déjà en mode dégradé puisque sur le serveur de la dernière chance.
Commande IPVSADM
L’utilitaire ipvsadm est toujours de la partie, je m’en sers pour avoir le status des virtual_server. (on peut configurer LVS avec mais franchement, autant passer par keepalived.conf). C’esun paquet à installer :
dnf install ipvsadm
Loadbalancer L7
Keepalived ne travaille qu’au niveau des couches TCP et IP. Si on veut faire du loadbalancing L7, il faudra ajouter un composant supplémentaire comme httpd ou haproxy. Cela est nécessaire par exemple si on veut faire de la persistence par cookie plutôt qu’en se basant sur l’IP source. Ce composant supplémentaire est installé sur les mêmes serveurs que keepalived :
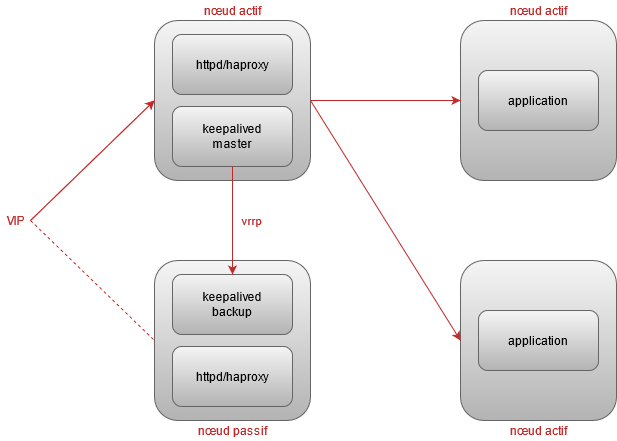
J’ai regardé vite fait haproxy qui est très populaire. Je n’ai pas vu de fonctionnalités spécifiques pour d’autre proctole que http. Pour le oueb, je suis plutôt habitué à utiliser le mod_proxy_balancer d’httpd qui marche vraiment trop bien. En plus, ce httpd qui fait reverse proxy peut rendre d’autres services (authentification, contenu statique, réécriture, etc).
Retour d’expérience
J’ai des keepalived en prod depuis presque deux ans, je n’ai rencontré qu’un bug sinon aucune autre difficulté sur les mises à jour, la disponibilité et les performances. Comparé avec le triplet pusle/nanny/piranha, on avait eu quelques incidents et surtout piranha était buggué à mort. Souvent, il vaut mieux un bon fichier de conf à une interface graphique (qui est encore moins utile avec le déploiement automatique).
Le bug que j’ai croisé concerne le misc_check : Si on atteint le timeout interne à keepalived sans que le script de check ne renvoie un code retour, alors on a un process keepalived qui reste “coincé” consommant du CPU mais n’impactant pas la dispo du service sur ce noeud. En ajustant les timeouts du script de check pour qu’ils soient toujours inférieur à la valeure configurer dans keepalived, on arrive à contourner le problème.
Contrairement à d’autre techno de loadbalancing, keepalived est plutôt sobre sur les requêtes de check. Avec l’option ha_suspend active, on a que le noeud master qui émet des requetes (check serveurs applicatifs et messages vrrp).
Autre point positif, c’est un service standard : un démon qu’on pilote avec systemctl, un fichier de conf dans /etc/, des logs dans /var/log/, c’est simple de transférer la compétence et l’exploitation.
Automatisation du déploiement
Il y a deux ans, j’ai profité d’une refonte complète d’architecture pour afin me mettre sérieusement au déploiement automatisé. Une fois qu’on y a gouté, impossible de revenir en arrière :) Mon besoin ne concernant que du failover sur du Red Hat 7, alors j’avais écrit un role Ansible plutot que d’en prendre un déjà existant (pas fan des roles multi OS). Avec le temps, mon role “tout simple” c’est étoffé de fonctionnalités et à dévié de l’idée originelle du truc le plus minimaliste possible :D
Je l’ai mis à disposition sur les deux plateformes si ça peut servir :
https://github.com/CNRS-DSI-Dev/simple-keepalived-ansible-role
https://galaxy.ansible.com/ggambini/simple_keepalived_ansible_role
Reste à faire
Dans le pipe, j’ai quelques pistes d’amélioration :
- Historiser les IP sources en mode source NAT car j’ai abandonné la technique de modifier la passerelle par défaut des serveurs finaux (voir épisode 1).
- Améliorer l’intégration avec nos outils de supervision, ça fait des années par exemple que je n’ai pas touché à snmpd.
- Pilotage du pool par le CI/CD : le truc qui me tente le plus, pouvoir sortir un real_server du pool avant de le redéployer, ça serait top (voir drainer les connexions si on veut pousser le truc).