
Cet article est le premier d’une petite série intitulée “Haute dispo de prolo” dont le but est d’avoir une infra robuste en utilisant simplement des logiciels open source et gratuits ainsi que des machines physiques simples sans stockage onéreux. Pour commencer, on va faire un load balancer façon BigIP F5 mais avec deux piotes VMs Linux, en mode j’ai pas de sous mais j’ai deux mains.
Introduction
Le load balancer est un élément indispensable d’une infrastructure un minimum robuste. Mais le petit problème c’est qu’un load balancer hardware va sûrement coûter plus cher que l’infra derrière … Comment avoir du failover, de la répartition de charges, tout ça ?? On va utiliser Piranha, une suite d’outils de clustering Linux chapeauté par une interface graphique rappelant vaguement celle des BigIP.
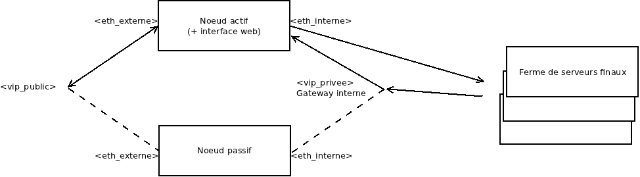
Pour cette article, nous utiliserons deux VMs installées sur SL6.3 et possédant deux interfaces réseaux, une pour le réseau interne et une pour sortir sur l’extérieur. L’idée est d’avoir une tête de réseau redondante et vérifiant l’état des serveurs finaux. Un petit schéma de principe pour fixer les différents noms utilisés par la suite :
Installation
L’installation est très légère mais il y a un peu de finitions à faire. On commence donc par installer les paquets qui vont bien sur chacun des nœuds :
yum install httpd php piranha ipvsadm rsync
chkconfig pulse on
Rsync servira à synchroniser la configuration mais ne sert pas directement pour Piranha.
Ensuite, on va autoriser le forwarding de paquets, ben ouais nos ptites VMs sont un peu des routeurs. On l’active en conf et aussi en live pour se dispenser d’un reboot. A faire sur les deux nœuds :
vim /etc/sysctl.conf
net.ipv4.ip_forward = 1
net.ipv4.conf.all.promote_secondaries = 1 (ligne à ajouter au fichier)
/sbin/sysctl -w net.ipv4.ip_forward=1
/sbin/sysctl -w net.ipv4.conf.all.promote_secondaries=1
On va permettre aux deux nœuds de causer entre eux sur le port 3636, nécessaire pour les mécanismes de détection quand un nœud tombe. De plus, comme les LBs seront la passerelle de sorties de nos serveurs finaux, il faut permettre le forwarding A faire sur les deux nœuds :
vim /etc/sysconfig/iptables
-A INPUT -m state --state NEW -m tcp -p tcp --dport 3636 -j ACCEPT
-A FORWARD -i eth1 -j ACCEPT
-A FORWARD -o eth1 -j ACCEPT
service iptables restart
On termine d’activer le NAT, cette fois on édite pas le fichier résultant des règles. On passe par le shell, c’est plus simple :
iptables -A POSTROUTING -o eth0 -j MASQUERADE
service iptables save
On démarre ensuite les services, on va pas le démarrer de la même façon sur les nœuds. Il y aura un nœud actif et un nœud passif. Sur le nœud actif :
ipvsadm --start-daemon master --mcast-interface <eth_interne>
Sur le nœud passif :
ipvsadm --start-daemon backup --mcast-interface <eth_interne>
Enfin, on démarre l’interface graphique sur le nœud principal et on en profite pour définir un password :
chkconfig piranha-gui on
/usr/sbin/piranha-passwd
service piranha-gui start
Le routage
Le routage est la méthode qui va être utilisée lorsque les serveurs finaux répondent aux requêtes traitées. Il y a trois méthodes proposées :
- La réponse directe : le serveur final répond directement au client, le client voit donc l’IP réelle du serveur final.
- Le tunneling : Le serveur final va répondre directement mais en passant par un tunnel jusqu’au LB.
- Le NAT : Le load balancer va natter les réponses des serveurs finaux, l’IP du serveur final n’est pas vu.
Dans mon infrastructure, j’ai très peu d’adresses IPv4 routables, la solution NAT permet de limiter le nombre d’adresses nécessaires, tout en offrant une gateway redondante pour les accès des serveurs finaux vers l’extérieur.Le tunneling aurait pu être choisit mais je ne vois pas de plus value par rapport à du NAT tout simple. Initialement, je voulais un couple LB + RP sur une même VM avec son équivalent en passif mais on est confronté à un problème de routage. En effet, il est nécessaire que la patte publique est comme gateway le routeur du subnet où l’on se trouve mais il faut aussi que la patte privée où écoutent les RP est comme gateway la VIP privée car on a du NAT en action. J’ai essayé mais à priori, il n’est possible d’avoir deux gateway de configurer …
Configuration du load balancer
La suite de la conf consiste à définir les services qui seront load balancer par Piranha. Tout cette étape se passe dans l’interface web de Piranha :
http://<ip_noeud_actif>:3636/
On se connecte avec le login “piranha” et le mot de passe définit plus haut avec la commande piranha-passwd. On arrive sur l’interface de gestion de notre load balancer, il y a 4 onglets : L’état du LB, le nœud actif, le nœud passif et les services load balancés :
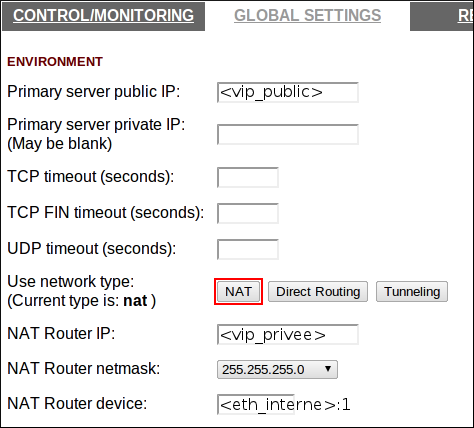
On va d’abord configurer les VIP dans la partie “GLOBAL SETTINGS”, on aura une VIP extérieure sur laquelle pointera nos CNames. Et on aura du NAT coté interne pour nos serveurs finaux, une passerelle sera créée par la suite dans les services load balancés. On définit les variables suivantes :
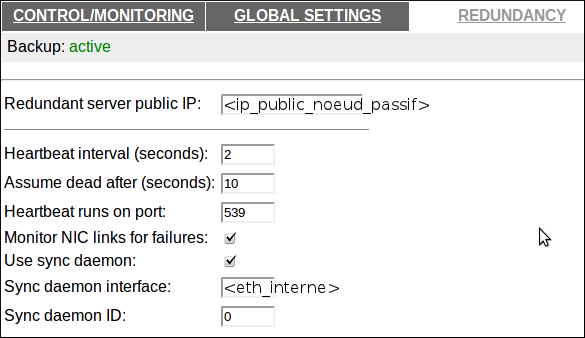
Puis, on va définir les informations concernant le nœud de secours (passif) dans la partie “REDUNDANCY”. On définit les variables suivants :
Configuration des virtuals servers
Les services load balancés correspondent à des virtuals servers déclarés dans la conf des LBs. On accède à cette configuration via l’onglet “VIRTUALS SERVERS”, pour commencer on va déclarer 3 VS : un coté interne pour la passerelle et deux autres cotés publiques en tant que frontal web. La cible :
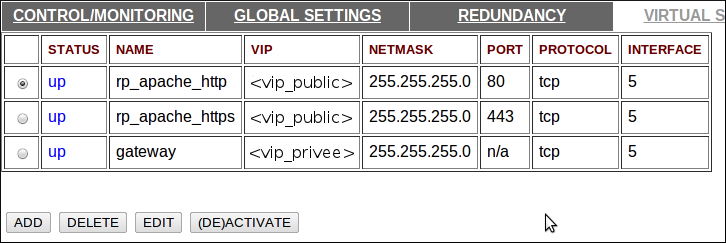
Ajouter un VS
Pour commencer, il faut cliquer sur “ADD” mais pas seulement, ça serait trop simple :-) Il faut ensuite sélectionner le service vierge et cliquer sur “EDIT”. On va commencer par créer notre “passerelle redondante”, ce service répond sur la <vip_privee>, par exemple 192.168.0.254. On ne spécifie pas de port en particulier et on crée une interface virtuelle
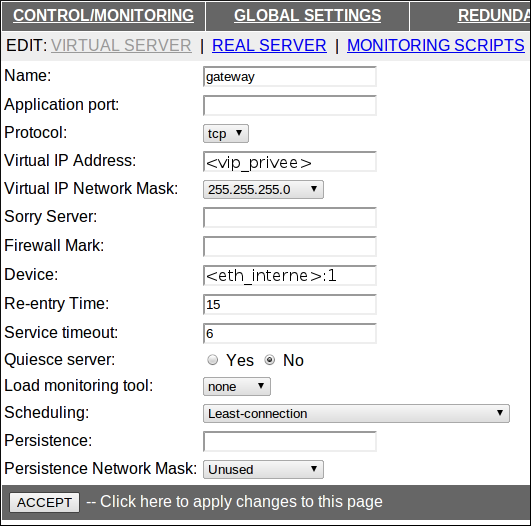
Il faut ensuite aller dans la partie “REAL SERVER”, pour déclarer les deux interfaces internes de nos LBs. Il faut arriver à cette configuration :
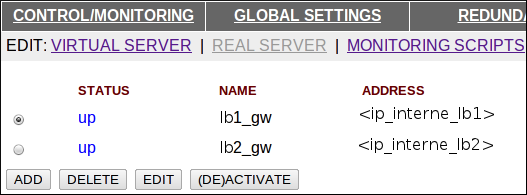
On ne modifie pas la partie “MONITORING SCRIPTS”, on laisse le check http par défaut. D’après mes tests, un LB détecte que son copain est tombé (via hearthbeat) et va sortir du pool les real servers qui ont la même IP. Donc même si le monitoring script test un port qui ne répond pas, le fail over marche quand même.
Terminer la conf des VS
Nous devons encore ajouter deux VS, un pour l’http et l’autre pour l’https. On va supposer que l’on a deux rerverse proxy Apache derrière nos LBs, ils ont des adresses non routables : <ip_interne_rp1> et <ip_interne_rp2>. Les deux VS vont se configurer de la même façon à une différence prêt : le script de monitoring. En effet, on va devoir utiliser un script spécifique pour monitorer le 443.
A la différence de la “passerelle redondante”, nos VS pour le web répondent sur la VIP publique et les serveurs finaux sont dans le réseau interne. On reprend la manip utilisée un peu plus haut pour créer un nouveau VS et y ajouter deux REAL SERVERs :
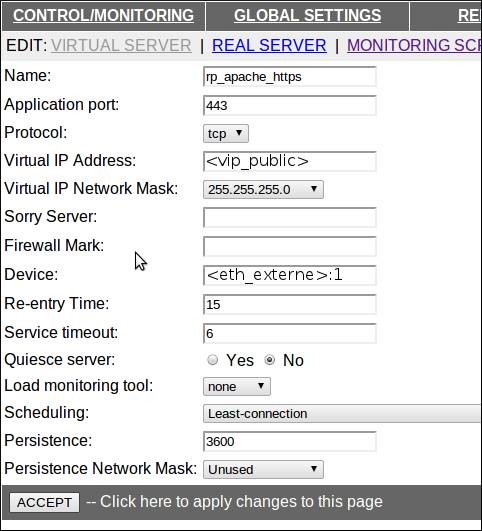
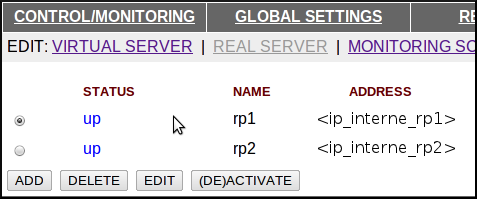
La configuration est la même pour le 443 (https), il faut cependant modifier la partie “MONITORING SCRIPTS”. Premièrement, on va créer un script sur le file system des deux LBs :
vim /etc/sysconfig/ha/lvs-check-https.sh
Le script est tout bête, il check le service et répond OK ou FAIL :
#!/bin/sh
TEST=$(
wget \
--connect-timeout=2 \
--no-check-certificate \
--save-headers \
--server-response \
--spider \
https://$1 2>&1 \
| grep -c "HTTP/1.1 200 OK"
)
if [ "$TEST" == "1" ] ; then
echo "OK"
else
echo "FAIL"
fi
Et on configure ce script dans l’interface piranha :
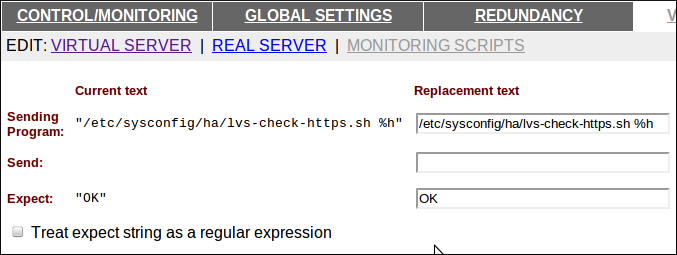
Synchronisation de la conf
Enfin, pour finir nos LBs hautement disponible, il faut que la configuration sur le nœud actif soit synchroniser sur le nœud passif. Pour se faire, on va simplement ajouter un rsync. On se connecte sur le nœud passif :
ssh-keygen -t dsa -b 1024
ssh-copy-id -i /root/.ssh/id_dsa.pub root@<ip_interne_lb1>
crontab -e
*/5 * * * * /usr/bin/rsync -r -e "ssh -i /root/.ssh/id_dsa" --delete -v root@<ip_interne_lb1>:/etc/sysconfig/ha/ /etc/sysconfig/ha > /dev/null
Conclusion
Pour pas un rond, on peut mettre le pied dans les infrastructures hautement disponibles. Les technos sous-jacentes à piranha ne sont pas très accessibles, Red Hat annonce entre 8 et 12 semaines de temps d’appropriation des outils de clustering. Cette sur couche graphique nous aide vraiment à maîtriser ces outils, vu les ptits objectifs de cet article.
On monte tranquillement notre infra hautement disponible, en commençant par la “porte d’entrée”. Je vais continuer ma série d’articles de la collection “haute dispo de prolo” :D Le prochain épisode traitera rapidement des reverse proxys, frontaux web effectuant une partie du travail, en particulier la gestion des accès.
Références
- Je me suis basé sur la documentation d’un collègue qui sera disponible ici sous peu : https://aresu.dsi.cnrs.fr/
- L’image du Tux Ché : http://yashton.deviantart.com/art/Che-Tux-Linux-Communism-SVG-45731368