
On a vu comment faire du load balancing pour pas cher dans notre premier article. Aujourd’hui, on va monter une plateforme de virtualisation libre, hautement disponible et surtout avec le moins de matos possible ! C’est aussi l’occasion pour moi de tester la version 3.1 de Proxmox.
Introduction
L’objectif ici est de créer un cluster Proxmox hautement disponible avec seulement deux serveurs physiques, du stockage local et des cartes réseaux compatibles IPMI. Le stockage sera répliqué par le réseau grâce à DRBD. Un pti schéma de principe pour fixer les variables utilisées par la suite :
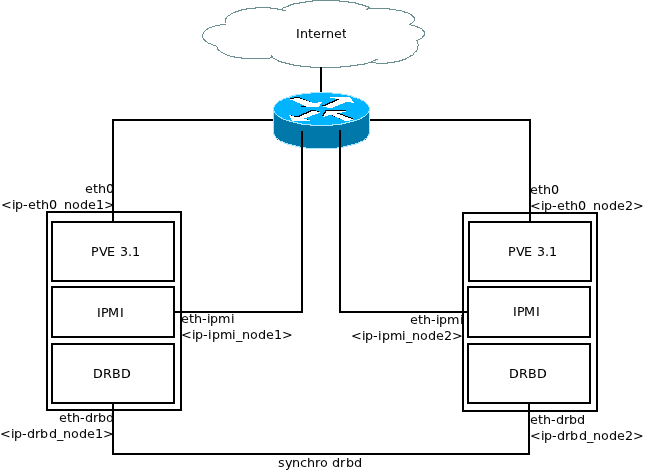
DRBD est définit comme étant du RAID1 par le réseau. Son utilisation ici nous permet de répliquer les données d’un nœud vers l’autre en temps réel (à un pti delta prêt), on peut donc migrer les VMs à chaud, il n’y a plus que la RAM a transférer.
IPMI est une série de fonctionnalités permettant de piloter une machine a distance comme les cartes DRAC de chez Dell par exemple. Afin d’assurer la cohérence des données, il est nécessaire d’avoir un mécanisme de “fencing”. Le fencing est l’action d’éteindre électriquement un nœud défaillant depuis un autre nœud, et donc de redémarrer une VM sur un autre nœud en toute sécurité (càd vis à vis des écritures concurrentes).
Pourquoi embarquer ces deux briques en plus de Proxmox ? On pourrait avoir du HA sans DRBD mais il faudrait alors un stockage réseau de type NAS, par exemple. On peut faire de la migration à chaud sans fencing mais il devient nécessaire pour le basculement automatique.
Choix du matériel
Il est possible de faire ce cluster avec n’importe quel matériel à condition de :
- Les processeurs des machines embarquent les instructions qui vont bien (VTx, etc).
- Les cartes réseaux supportent les instructions IPMI.
- Les cartes RAID permettent de faire deux containers distincts ou alors avoir deux disques physiques par machine.
Pour un environnement de production, il faudra du matériel plus robuste. C’est à dire avoir une alimentation redondante, du RAID au niveau du stockage et pourvoir faire du bonding avec les interfaces réseaux. Deux serveurs Dell d’entrée de gamme, type R420 ou R720 font parfaitement l’affaire. Ils proposent la redondance nécessaire, sont compatibles IPMI et leurs disques locaux sont très performants.
La première partie de l’article est une maquette pour tester la solution. Dans la suite, on ajoutera des mécanismes pour renforcer la solidité de la solution.
Configuration du cluster
Installation de Proxmox 3
J’ai une petite doc d’installation de PVE 2, avec pleins de captures d’écran. La version 3 s’installe exactement de la même façon, il faut juste veiller à sélectionner le bon disque dur (dans la majorité des cas /dev/sda).
Mise à jour du système
On fait une petite mise à jour système avant de poursuivre l’installation :
apt-get update
apt-get dist-upgrade
apt-get install vim lshw
Configuration du réseau
L’interface eth0 est configurée pendant l’install de Proxmox, on va avoir besoin d’une interface supplémentaire directement reliée à l’autre nœud. J’ai utilisé lshw pour trouver l’interface dont j’ai besoin car sur ses serveurs, il y a de nombreuses pattes réseaux. Dans mon cas, eth4 correspond aux ports 10G reliés entre eux. On la configure pour chaque nœud :
vim /etc/network/interfaces
Pour le nœud 1 :
auto <eth-drbd>
iface <eth-drbd> inet static
address <ip-drbd_node1>
netmask 255.255.255.0
Pour le nœud 2 :
auto <eth-drbd>
iface <eth-drbd> inet static
address <ip-drbd_node2>
netmask 255.255.255.0
On redémarre le réseau :
service networking restart
Création du cluster Proxmox
Sur le noeud 1, on crée le cluster :
pvecm create <cluster_name>
Surle noeud 2, on rejoint le cluster :
pvecm add <ip-eth0_node1>
Configuration de la brique DRBD
Avant de continuer, on va s’attaquer à la partie DRBD, c’est à dire la réplication des données entre les deux nœuds Proxmox. L’idée ici est de créer deux partitions DRBD, une pour les VMs du nœud 1 et l’autre pour les VM du nœud 2. Proxmox est installé sur /dev/sda et la partie DRBD sera sur /dev/sdb.
Pour commencer, on crée deux partitions de taille égale sur /dev/sdb :
fdisk
n
p
1
+<taille_drbd>GB
Puis on en crée une deuxième :
n
p
2
+<taille_drbd>GB
w
On fait exactement la même chose sur le deuxième nœud, avec les mêmes tailles de partition. On a donc un /dev/sdb1 et un /dev/sdb2 sur les deux nœuds.
Puis on installe DRBD :
apt-get install drbd8-utils
Éditer le fichier de conf principal et remplacer le contenu par :
global {
usage-count no;
}
common {
syncer {
rate 30M;
verify-alg md5;
}
}
Puis créer un fichier pour la partition /dev/sdb1, qui sera mappée sur /dev/drdb1 :
vim /etc/drbd.d/r1.res
Avec le contenu suivant :
resource r1 {
protocol C;
startup {
wfc-timeout 0; # non-zero wfc-timeout can be dangerous (http://forum.proxmox.com/threads/3465-Is-it-safe-to-use-wfc-timeout-in-DRBD-configuration)
degr-wfc-timeout 60;
become-primary-on both;
}
net {
cram-hmac-alg sha1;
shared-secret "my-secret";
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
on <name_node1> {
device /dev/drbd1;
disk /dev/sdb1;
address <ip-drbd_node1>:7788;
meta-disk internal;
}
on <name_node2> {
device /dev/drbd1;
disk /dev/sdb1;
address <ip-drbd_node2>:7788;
meta-disk internal;
}
}
On utilise les IPs des interfaces dédiés, ici eth4. Faire de même pour la partition /dev/sdb2 qui sera mappée sur /dev/drbd2 :
vim /etc/drbd.d/r2.res
Avec le contenu suivant :
resource r2 {
protocol C;
startup {
wfc-timeout 0; # non-zero wfc-timeout can be dangerous (http://forum.proxmox.com/threads/3465-Is-it-safe-to-use-wfc-timeout-in-DRBD-configuration)
degr-wfc-timeout 60;
become-primary-on both;
}
net {
cram-hmac-alg sha1;
shared-secret "my-secret";
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
}
on <name_node1> {
device /dev/drbd2;
disk /dev/sdb2;
address <ip-drbd_node1>:7789;
meta-disk internal;
}
on <name_node2> {
device /dev/drbd2;
disk /dev/sdb2;
address <ip-drbd_node2>:7789;
meta-disk internal;
}
}
:!: Il faut un port pour chaque ressource DRBD, donc ici le port 7788 pour r1 et 7789 pour r2.
Ensuite, on démarre le démon et on crée les ressources :
/etc/init.d/drbd start
drbdadm create-md r1
drbdadm create-md r2
drbdadm up r1
drbdadm up r2
Ensuite, on check que DRBD est opérationnel :
cat /proc/drbd
version: 8.3.13 (api:88/proto:86-96)
GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:51
1: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:87887904
2: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:87887904
Nos deux ressources sont bien connectées mais pas synchronisées. On lance sur synchro sur le nœud 1 et seulement celui ci :
drbdadm -- --overwrite-data-of-peer primary r1
drbdadm -- --overwrite-data-of-peer primary r2
Après la synchro, il est conseillé de stopper et démarrer les démons sur les deux nœuds pour voir si la conf primaire/primaire fonctionne :
/etc/init.d/drbd stop
/etc/init.d/drbd start
cat /proc/drbd
On doit voir ça :
version: 8.3.13 (api:88/proto:86-96)
GIT-hash: 83ca112086600faacab2f157bc5a9324f7bd7f77 build by root@sighted, 2012-10-09 12:47:51
1: cs:Connected ro:Primary/Primary ds:UpToDate/UpToDate C r-----
ns:16 nr:0 dw:16 dr:1296 al:1 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
2: cs:Connected ro:Primary/Primary ds:UpToDate/UpToDate C r-----
ns:16 nr:0 dw:16 dr:1000 al:1 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:0
Sur un seul nœud, On ajoute un volume physique sur nos deux ressources DRBD :
pvcreate /dev/drbd1
pvcreate /dev/drbd2
vgcreate drbd1vg /dev/drbd1
vgcreate drbd2vg /dev/drbd2
Ensuite, on vérifie la conf avec pvscan :
pvscan
PV /dev/drbd2 VG drbd2vg lvm2 [83.81 GiB / 83.81 GiB free]
PV /dev/sda2 VG pve lvm2 [99.50 GiB / 12.50 GiB free]
PV /dev/drbd1 VG drbd1vg lvm2 [83.81 GiB / 83.81 GiB free]
Total: 3 [267.12 GiB] / in use: 3 [267.12 GiB] / in no VG: 0 [0 ]
Pour finaliser cette partie, il faut aller dans l’interface graphique de Proxmox. Connectez vous sur l’un des deux nœuds en https, port 8006, cliquez sur “Datacenter” dans le cadre de gauche, puis sur l’onglet “Storage” et enfin choisissez d’ajouter un groupe LVM :
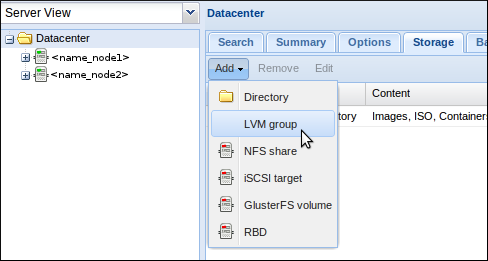
On retrouve ici nos deux VG créés un peu plus tôt. Pour chacun, il faut donner un ID (attention, plus moyen de le modifier après) et cliquez sur “Shared” :
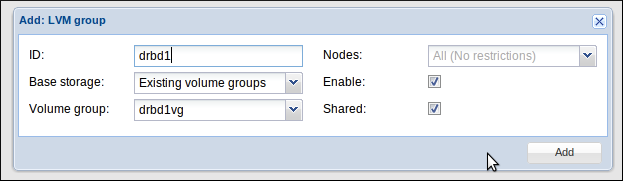
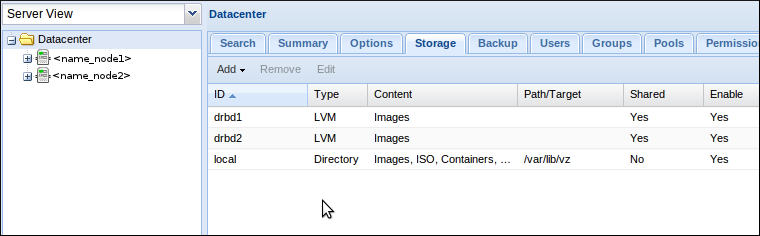
On répète ça pour le deuxième VG, au final on doit avoir cette configuration :
Configuration de la brique IPMI
:!: Si votre serveur possède une carte iDRAC, la configuration va être écrasée par la conf IPMI.
On installe le paquet ipmitool qui va permettre de configurer la fonction sur la carte réseau :
apt-get install ipmitool
Message d’erreur à la fin, pas de /dev/ipmi0, faut lancer modprobe :
modprobe ipmi_si
modprobe ipmi_devintf
On configure le réseau :
ipmitool lan set 1 ipaddr <ip-ipmi_node1>
ipmitool lan set 1 netmask 255.255.255.0
On configure l’utilisateur :
ipmitool user set password 2 <password-ipmi_root>
:?: L’ID 2 correspond au compte root, le compte par défaut IPMI.
On active la carte :
ipmitool lan set 1 access on
On test depuis le second noeud :
ipmitool -H <ip-ipmi_node1> -U root -P <password_ipmi_root> power status
Chassis Power is on
A refaire sur le nœud 2. Après reboot, le module n’est plus chargé mais à priori la conf IPMI reste active. Il faut juste ajouter le champs -H <ip-ipmi_local> pour les commandes ipmitool.
Configuration du fencing
Il faut activer cette option en la décommentant dans redhat-cluster-ve :
vim /etc/default/redhat-cluster-pve
fence_tool join
On va modifier le fichier cluster.conf. Il y a un système de versionning, il faut d’abord créer un nouveau fichier :
cp /etc/pve/cluster.conf /etc/pve/cluster.conf.new
Ensuite, on l’édite et on incrémente la version :
vim /etc/pve/cluster.conf.new
<cluster name="<cluster_name>" config_version="<version+1>">
On modifie la ligne CMAN (cluster manager redhat) :
<cman keyfile="/var/lib/pve-cluster/corosync.authkey" two_node="1" expected_votes="1">
On déclare les interfaces IPMI, juste après la directive :
<fencedevices>
<fencedevice agent="fence_ipmilan" ipaddr="<ip-ipmi_node1>" login="root" name="ipminode1" passwd="<password-ipmi_root>" />
<fencedevice agent="fence_ipmilan" ipaddr="<ip-ipmi_node2>" login="root" name="ipminode2" passwd="<password-ipmi_root>" />
</fencedevices>
On lie ces interfaces de fencing avec les nœud du cluster :
<clusternodes>
<clusternode name="<name_node1>" votes="1" nodeid="1">
<fence>
<method name="1">
<device name="ipminode1"/>
</method>
</fence>
</clusternode>
<clusternode name="<name_node2>" votes="1" nodeid="2"/>
<fence>
<method name="1">
<device name="ipminode2"/>
</method>
</fence>
</clusternode>
</clusternodes>
Il faut maintenant activer cette nouvelle version de la configuration du cluster, connectez vous à l’interface web Proxmox. Cliquez sur “Datacenter” dans le cadre de gauche, puis sur l’onglet “HA”. Sur cet écran, vous pouvez voir la nouvelle conf, ainsi qu’un diff avec la version précédente. Cliquez sur “Activate” pour appliquer les modifications :
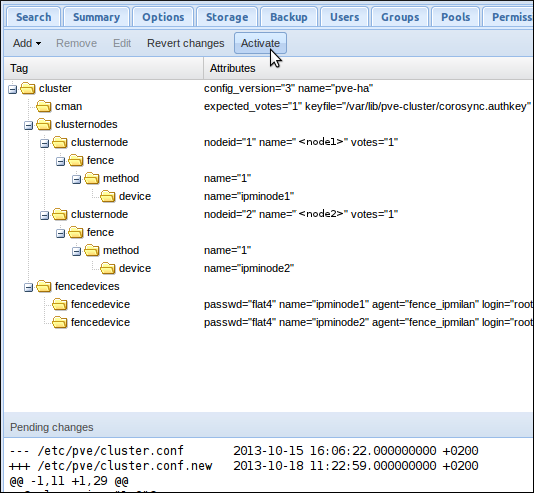
:?: Si vous avez une erreur lorsque vous cliquez sur l’onglet “HA”, vous avez sûrement une erreur de syntaxe dans le fichier cluster.conf.
On peut tester que le fencing fonctionne. Pour cela sur le nœud 1, on lance la commande (<name_node2> est le nom du nœud dans cluster.conf) :
fence_node <name_node2>
La commande doit retourner “fence <name_node2> success” et le nœud 2 doit être injoignable. On relance le nœud 2 depuis le nœud 1 avec ipmitool :
ipmitool -H <ip-ipmi_node2> -U root -P <password-ipmi_root> power on
Nos 3 “briques” sont installées et configurées (PVE, DRBD, IPMI), on reboot les deux machines car le démon rgmanager ne démarre pas tout seul et le démarrer manuellement ne semble pas être la bonne chose à faire.
Ajout d’un serveur de quorum
Mon objectif est de faire l’architecture la plus simple possible sans sacrifier la disponibilité. Mais au vue des premiers tests de basculement, il est indispensable d’ajouter un quorum dans l’architecture. En effet, on se rend vite compte que certains scénarios ne fonctionnent pas. Par exemple, si on simule une coupure électrique sur le nœud 1, le nœud 2 détecte la défaillance mais ne va pas basculer les VMs. Le nœud 2 ne sait pas si le nœud 1 est vraiment défaillant ou si il est lui même défaillant.
Avec l’ajout d’un quorum, un nœud du cluster pourra s’assurer qu’il n’est pas isolé du réseau en contactant ce quorum. Donc, dans le cas d’une défaillance du nœud 1, le nœud 2 pourra prendre la décision de basculer les VMs car il a perdu contact avec le noeud 1 mais peut contacter le quorum. Le petit schéma mis à jour :
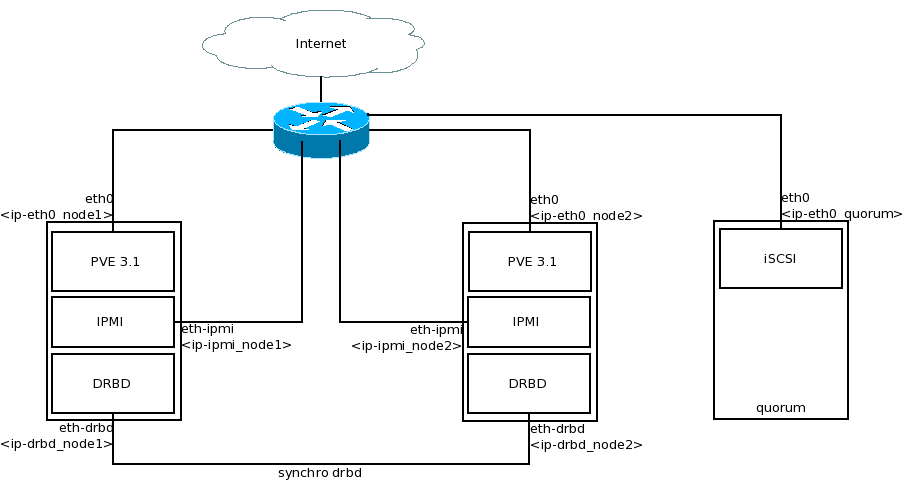
J’ai donc monté une troisième machine avec un serveur qui trainait à coté, c’était plus simple pour moi que de créer une VM ailleurs et ouvrir le réseau. Cette brique n’est pas critique, elle peut être hébergée sur une VM ou une machine physique. Donc, le point de départ de cette partie est un système RHEL6 like tout neuf. Il faut créer un LV de petite taille dédié pour le iSCSI sur le serveur de quorum :
lvcreate -n pve_quorum -L 10M <mon_vg>
On installe la partie iSCSI et on configure la ressource :
yum install scsi-target-utils -y
chkconfig tgtd on
vim /etc/tgt/targets.conf
Avec la conf suivante :
<target <ip-eth0_quorum>>
backing-store /dev/<mon_vg>/pve_quorum
initiator-address <ip-eth0_node1>
initiator-address <ip-eth0_node2>
</target>
On démarre le service et on vérifie avec la commande tgt-admin que le LUN est bien dispo :
service tgtd start
tgt-admin -s
Ensuite, on installe le client iSCSI sur les deux noeuds Proxmox :
aptitude install tgt
On édite la conf et on remplace manuel par automatic pour la directive node.startup :
vim /etc/iscsi/iscsid.conf
node.startup = automatic
On liste les LUN dispos sur le serveur de quorum :
iscsiadm --mode discovery --type sendtargets --portal <ip-eth0_quorum>
On redémarre le service tgt sur les noeuds Proxmox et on fonce voir les logs :
/etc/init.d/open-iscsi restart
tail -f /var/log/dmesg
sd 8:0:0:1: [sdc] 24576 512-byte logical blocks: (12.5 MB/12.0 MiB)
sd 8:0:0:1: [sdc] Attached SCSI disk
:?: Dans les logs, on nous indique le nom local de la ressource iSCSI, ici /dev/sdc.
Sur le noeud 1 Proxmox, on partitionne /dev/sdc :
fdisk /dev/sdc
n
p
1
w
Puis on le “formate” en tant que quorum :
mkqdisk -c /dev/sdc1 -l pve_quorum
On va modifier la conf du cluster Proxmox pour la prise en compte du quorum :
cp /etc/pve/cluster.conf /etc/pve/cluster.conf.new
vim /etc/pve/cluster.conf.new
Premièrement, il faut incrémenter la version du fichier de configuration dans la directive
<?xml version="1.0"?>
<cluster config_version="5" name="pve-ha">
<cman expected_votes="3" keyfile="/var/lib/pve-cluster/corosync.authkey"/>
<quorumd votes="1" allow_kill="0" interval="1" label="pve_quorum" tko="10"/>
<totem token="54000"/>
<clusternodes>
...
On active la conf, toujours sur le nœud 1, comme dans la partie sur le fencing.
On redémarre les services rgmanager et cman (l’arret de rgmanager fait basculer les VMs HA, la copie vers l’autre noeud peut prendre du temps) :
/etc/init.d/rgmanager stop
/etc/init.d/cman reload
Ou plus simplement, on redémarre le nœud :
reboot
Si on lance la commande clustat, on doit voir nos deux noeud et le quorum :
clustat
Cluster Status for pve-ha
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
<name_node1> 1 Online, Local, rgmanager
<name_node2> 2 Online, rgmanager
/dev/block/8:33 0 Online, Quorum Disk
Bien, passons aux tests !!
Créer une VM et tester la migration à chaud
Maintenant, on va passer au chose sérieuse et pour tester nous avons besoin d’une VM en état de marche. Copiez une ISO dans le répertoire /var/lib/vz/template/iso/. Puis via l’interface Proxmox, cliquez sur “Create VM” en haut à droite. Il faut simplement veiller à choisir le bon stockage dans l’onglet “Hard Disk”, menu déroulant “Storage”. Si je crée une VM sur le nœud 1, alors le stockage sera drbd1, si c’est le nœud 2 alors c’est drbd2. Il est conseillé de séparer de cette façon, en cas de pépin sur une ressource drbd, on a pas toutes nos VM en vrac.
Une fois la VM créée, installée et démarrée, on peut tester la migration à chaud. Pour se faire, il faut cliquer sur “Migrate” en haut à droite une fois qu’on est sur la vue VM. Cochez “Online” et lancez la migration :
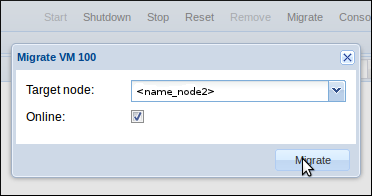
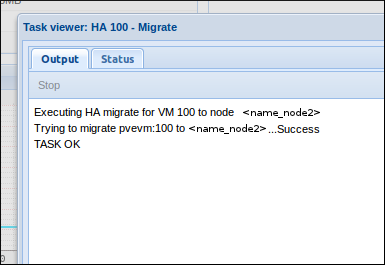
La VM est basculée sur le nœud 2 sans interruption (test avec un ping UDP, il y a juste un paquet qui met 150ms) :
Tester la haute disponibilité
Pour que Proxmox bascule automatiquement cette VM en cas de défaillance du nœud qui l’héberge, il faut l’ajouter dans le pool des VM HA. Cliquez sur “Datacenter”, puis sur l’onglet HA et dans le menu “Add”, cliquez sur “HA managed VM/CT” :
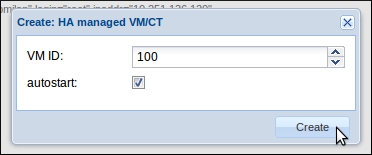
Entrez l’ID de votre VM, 100 pour a première, puis validez :
A tout moment, on peut vérifier l’état de notre cluster avec la commande clustat :
clustat
Qui répond dans notre cas, sur le nœud 2 :
clustat
Cluster Status for pve-ha @ Tue Oct 22 10:35:19 2013
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
<name_node1> 1 Online, rgmanager
<name_node2> 2 Online, Local, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
pvevm:100 <name_node1> started
La bascule automatique n’est pas instantanée, contrairement à la migration a chaud, il va y avoir une interruption de service. Sur mes tests, j’ai perdu environ 45 packets UDP, sachant que par défaut la commande ping attend 1s entre chaque packets et que le timeout par défaut semble être de 4 secondes, on a au maximum une interruption de 4 minutes.
J’ai refais un essai, en spécifiant le timeout à 1 seconde et l’interval à 1 seconde avec la commande suivante :
ping -t 1 -W 1 <ip_vm-ha>
J’ai perdu 51 packets, on peut donc estimer que la coupure à durée moins de 2 minutes. Le scénario a été de déconnecter physiquement eth0 du nœud hébergeant la VM HA. J’ai testé aussi avec la commande “service networking stop”. Le noeud défaillant est redémarré via IPMI et est de nouveau opérationnel peu de temps après.
Par contre le scénario “arrêt électrique violent” d’un des noeuds ne fonctionne pas, la faute au fencing ! Je n’ai qu’une alimentation sur mes serveurs, si je la déconnecte, la partie IPMI ne répondra plus non plus. Hors, si le noeud vivant n’arrive pas à effectuer le fencing, alors il ne bascule pas les VMs. C’est un cas de figure un peu embêtant, mais il vaut peut être mieux ne pas basculer les VMs que de prendre le risque d’éclater le filesystem partagé ?
Conclusion
Pour une fois, on va finir l’article avec une grosse conclusion. Je m’étais essayé aux outils de clustering RedHat et DRBD sans succès, ce sont des technos dures d’accès. Ici, j’ai suivi principalement la doc officielle Proxmox et on arrive très facilement à mettre en œuvre la partie DRBD, un bon point ! De façon générale, la doc est aux petits oignons et nous permet au final de monter un petit cluster fonctionnel.
Le fencing me semble être le point faible de cette architecture, car certains scénarios ne fonctionnent pas. En tout cas, il est suffisant pour les incidents sur la couche système. Par contre en cas de défaillance électrique ou d’un équipement réseau actif, c’est à dire un défaut de la couche physique, le fencing peut échouer et ne pas déclencher le failover des VMs. Nénamoins, il est indispensable d’utiliser le fencing car nos ressources DRBD sont en master/master !!
J’ai eu quelques soucis de split brain avec DRBD qu’il est très facile à corriger sur un environnement de test. Mais en prod avec de gros volumes, ça sera aussi simple ? Le démon rgmanager ne démarre pas en CLI et si on le redémarre, le failover est déclenché. Le plus simple est de rebooter le nœud Proxmox et tout démarre sans encombre.
Je ne pense pas que l’on puisse changer le mécanisme de fencing sans mettre en péril l’intégrité des données. De plus, le fencing va aussi être déclenché quand le nœud défaillant va revenir à la vie, DRBD et rgmanager s’initialiseront parfaitement au reboot du nœud.
Pour finir, on m’a déconseillé au plus au point de faire du HA en production. Après ces petits tests, je ne serais pas aussi catégorique même si je ne peux pas vous dire de foncer les yeux fermés. A mon avis, pour se lancer avec du Proxmox HA en prod, il faut un bon hébergement, des alims redondantes sur les nœuds Proxmox voir les équipements réseaux et faire du bonding sur les interfaces réseaux. Et beaucoup de temps pour tester tous les cas de figure :-)
Et je tiens a préciser que c’est des problématiques qui ne sont pas propre au logiciel en particulier. Vous rencontrerez les mêmes problèmes avec votre vmware si vous voulez de la haute dispo sans NAS ou SAN.
Références
- Partie DRBD : http://pve.proxmox.com/wiki/DRBD
- Partie IPMI : http://blog.crifo.org/post/2010/04/02/Configurer-IPMI-simplement
- Partie fencing : https://access.redhat.com/site/documentation/en-US/Red_Hat_Enterprise_Linux/5/html/Configuration_Example_-_Fence_Devices/IPMI_config_file.html
- Fencing suite : http://pve.proxmox.com/wiki/Fencing#IPMI_.28generic.29
- L’image du Tux Ché : http://yashton.deviantart.com/art/Che-Tux-Linux-Communism-SVG-45731368